Vector databases
Vector databases
Vector databases perform data index based on data vectors (or vector embeddings), which is a difference to what other databases do. A vector database performs storing, indexing, and searching across a massive dataset of unstructured data that leverages the power of embeddings from machine learning models.
The relation with LLMs is that LLMs can be used to generate embeddings datasets, which capture the meaning and context of data.
Typical use cases of vector databases include:
- Semantic search: search text ranked by semantic similarity.
- Recommendation: return items with text attributes similar to the given text.
- Classification: return the class of items where the text attributes are similar to the given text.
- Clustering: cluster items whose text attributes are similar to the given text.
- Outlier Detection: return items where text attributes are least related to the given text.
It is typical to use LLMs to get an embedding dataset and then use a vector database to perform for example semantic search.
Semantic search is a type of search that uses the meaning of words to find relevant results. Typically semantic search is done in two steps:
- Step 1: generate embeddings dataset (for example, with LLM).
- Step 2: perform semantic search using Google ScaNN OSS, or Vertex AI Matching Engine. An index with ScaNN is expected to get lower recall, thanks to the anisotropic loss calculation.
Pinecone
Pinecone is a company based in Israel which offers a vector database for vector search. Its product is available in the Google Cloud marketplace
This is a comparison between Pinecone and Vertex AI Matching Engine. This comparison includes some misunderstandings:
- No mention to QPS. When high enough QPS is required (a few hundreds or more) on a large enough dataset (1 million or more), Vertex AI Matching Engine is just much cheaper.
- Vertex Matching Engine now supports real-time indexes.
The performance advantage of Vertex AI Matching Engine comes at the cost of longer indexing building time. Vertex AI Matching Engine spends the time to sample the dataset in order to build indexes with better performance & higher recall, but don’t need more samples beyond a certain number, so the indexing time doesn’t grow linearly with the size of the dataset. e.g. it takes only a few hours to build an index of billions of vectors.
ScaNN
ScaNN (Scalable Nearest Neighbors) is an open-source library and method for efficient vector similarity search at scale, using quantization. Quantization based techniques are the current state-of-the-art for scaling maximum inner product search to massive databases.
pip install scannIt implements anisotropic loss (see details on blog), which puts higher penalty to the error that is parallel to the original vector (i.e. we penalize the distance, less the direction). This has demonstrated to increase the recall rate. Basically, it adds search space pruning and quantization for Maximum Inner Product Search.
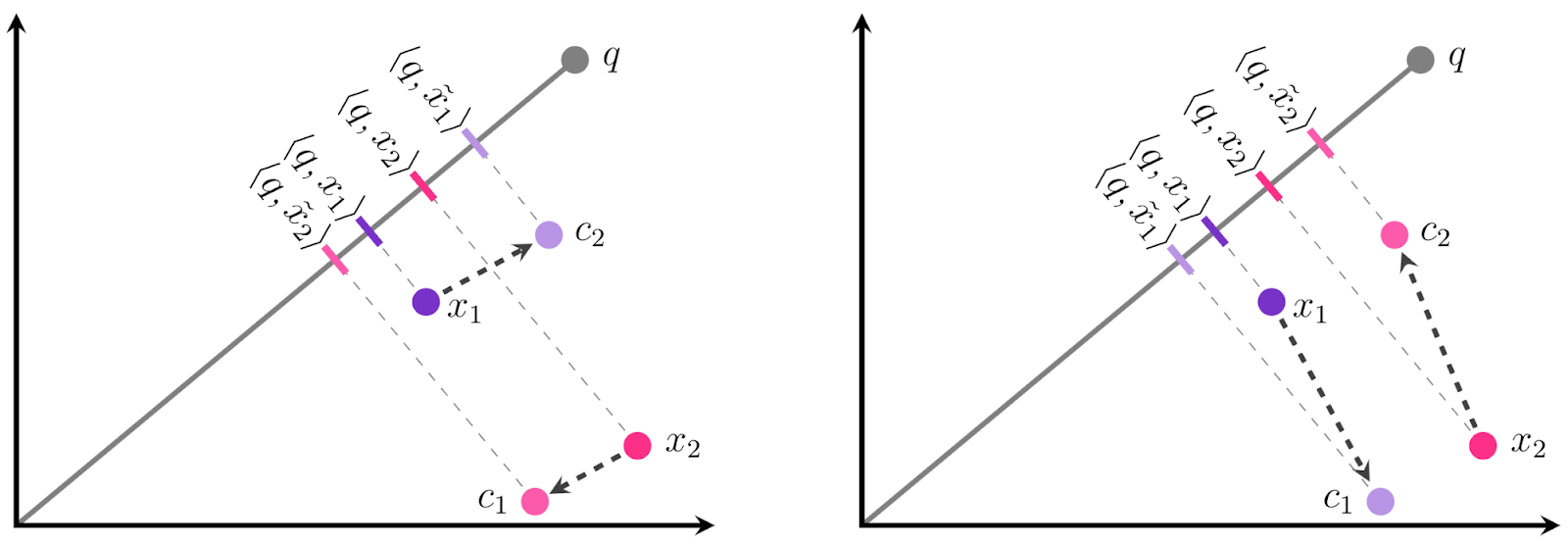 |
|---|
| Fig.1 ScaNN anisotropic loss |
ScaNN open-source library can be found here. A notebook example can be found here.
ScaNN achieves state-of-the-art performance on ann-benchmarks.com as shown on the glove-100-angular dataset.
Vertex AI Matching Engine
Vertex AI Matching Engine implements ScaNN at scale, providing a high-scale low latency vector database. It performs approximate nearest neighbor (ANN) service match, unlike kNN since that is expensive to compute.
Use cases for high-scale vecrot databases include recommendation engines, search engines, ad targeting systems, …
For example, for a high traffic web site, given a query item, Matching Engine finds the most semantically similar items to it from a large corpus of candidate items.
A key requirement to create an index with low latency is VPC peering, however, other two connectivity options are in public beta:
- Public endpoints: allows to setup and serve match queries without going through the complex VPC peering setup process.
- Private service connect.#
A basic tutorial for indexing implementation can be found here.
Public code samples can be found in the references section.
Chroma
Chroma is a vector database, a start-up company based in San Francisco, that raised $18M seed funding recently.
It’s more limited than Pinecone, does not have a hosted version, and lacks of integration with other systems.
pip install chromadbRefer to starting guide here.
Other vector databases: Weaviate and Milvus
Weaviate is a company based in The Netherñands that provides an open-source vector database. It allows storing data objects and vector embeddings from ML-models and scales seamlessly to billions of data objects.
Weaviate announced their database to be deployed in a customer VPC on GKE as a managed solution on Google Cloud. Details on PaLM API integration can be seen here.
Milvus is an open-source, high scalable vector database to store a huge amount of vector-based memory and provide fast relevant search.
References
[1] List of vector databases integrated by Langchain
[2] Medium blog post: All you need to know about Google Vertex AI Matching Engine
[3] Google Cloud blog: Mercari leverages Google’s vector search technology to create a new marketplace
[4] Vertex AI Matchine Engine public demo
[5] Google Cloud Vertex Github Community Matching Engine samples
[6] Google Cloud Vertex Github Official Matching Engine samples